

В начале 2000-х годов в мире компьютерной индустрии появилась технология GPGPU (от англ. general-purpose graphics processing units), которая активно развивается и по сегодняшний день. Ее основой является перенос не графических вычислений на графический процессор (GPU, от англ. graphics processing unit) который, в отличие от центрального (CPU, от англ. central processing unit), обладает множеством маленьких ядер (выступающих в виде ковейера), потребляющих не большое количество энергии [1]. В связи с этим GPU заметно выигрывает в производительности на ватт потребляемой мощности. Джек Донгарр, директор Инновационной вычислительной лаборатории университета штата Теннеси заметил, что “GPU уже достигли той точки развития, когда многие приложения реального мира могут с легкостью выполняться на них, причем быстрее, чем на многоядерных системах. Будущие вычислительные архитектуры станут гибридными системами с графическими процессорами, состоящими из параллельных ядер и работающими в связке с многоядерными CPU”[2].
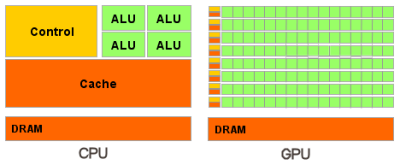
Рисунок 1. Отличительная особенность GPU от CPU.
Из-за архитектурной особенности GPU оптимизирован для параллельной обработки данных, в отличие от последовательной обработки, выполняемой CPU. Стоит заметить, что в большинстве случаев графический процессор не является заменой центральному, а скорее выполняет роль вычислительного блока и работает одновременно с ним. В настоящее время существуют разработки, в которых оба процессора объединены в одно устройство, называемое APU (от англ. accelerated processing unit).
В компьютерной индустрии существует несколько крупных продуктов, которые реализуют концепцию GPGPU:
- CUDA (от англ. Compute Unified Device Architecture);
- OpenCL (от англ. Open Computing Language);
- DirectCompute и C++ AMP;
-
OpenACC.
Все вышеперечисленные продукты условно можно разделить на три категории: аппаратно-зависимые (CUDA), программно-зависимые (C++ AMP) и универсальные (OpenCL, OpenACC), однако все они позволяют разработчикам создавать приложения, использующие графический процессор в качестве вычислительного блока. Далее рассмотрим основные сферы применения и преимущество, получаемое, в ходе использования GPU.
Развлечения и мультимедиа.
По большому счету развлечения и мультимедиа являются одним из двигателя прогресса графических вычислений. Необходимо за короткий интервал времени выполнить огромные вычисления для рендеринга игрового пространства или анимации. Все большее количество игр возлагают пересчет на графический процессор. Для этих целей компания Nvidia предлагает игровой движок PhysX, который позволяет значительно ускорить игровую физику.
Все большее количество разработчиков конвертеров аудио и видео используют вычислительную мощность графического процессора. К примеру для конвертирования двухчасового видео может потребоваться более пяти часов работы центрального процессора. Используя GPU можно ускорить конвертацию видео до 20 раз при этом CPU не будет нагружен и сможет выполнять другие пользовательские задачи.
Зачастую проходит большое количество времени после съемок фильма до финального показа. Создатели фильма «Повелитель стихий» сообщили, что «Моделирование огня и движения жидкости обычно очень сложно и требует от специалиста глубокого понимания алгоритмов гидродинамики, а также огромного опыта в области технической реализации визуальных эффектов. Кроме того, традиционные решения для визуализации, основанные на вычислениях на центральном процессоре, делают процесс создания эффектов чрезвычайно трудоёмким и затратным по времени, что ограничивает творческий потенциал создателей и является непозволительной роскошью в киноиндустрии.»[3] Используя CUDA в своей работе им удалось добиться реалистичных эффектов и значительно сократить время их создания.
Наука и медицина.
Распараллеливание алгоритмов само по себе является научной задачей. Необходимо выбрать правильные критерии для разбиения последовательного алгоритма на множество мелких задач, выполняемых параллельно. Однако многие научные программы, например Mathematica, Maple, MATLAB и Mathcad Prime, уже во всю используют вычислительную мощь графических процессорав.
Множество университетов (например Северо-Восточный университет, институт Макса Планка, Гарвард и другие) используют GPU в своих научных целях. В университете Иллинойса была разработана программа NAMD (Nanoscale Molecular Dynamics) для моделирования вируса. Работа NAMD была ускорена почти в 12 раз благодаря CUDA и в целом показала прирост скорости в 330 раз по сравнению с одноядерным CPU при запуске на кластере с GPU-ускорением в Национальном центре суперкомпьютерных приложений (NCSA).
Графическая вычислительная мощь помогает в борьбе за человеческую жизнь, обнаруживая злокачественные новообразования в 100 раз быстрее, чем CPU. Лаборатория биофотоники Института прикладной физики РАН занимается разработкой методик и созданием приборов для оптической биомедицинской диагностики. Используя GPU в качестве вычислителя был достигнут более чем стократный прирос производительности, сократив время получения результата до 1,5 минут.
В трехмерном ультразвуковом сканировании компании TechniScan используется графический процессор для ускорения обработки. Американский национальный институт по изучению раковых заболеваний заявил о 12-ти кратном ускорении вычисления связывания протеинов, которые используются для разработки новых лекарств от таких болезней как рак или болезнь Альцгеймера. Университет Гронингена, эмулируя сетчатку глаза, сталкивается с обработкой большого количества информации одновременно. Выполнение обработки подобной информации на CPU является ресурсоемким процессом, поэтому идеальным выбором является выполнение обработки параллельно на GPU.
Заключение.
В настоящее время графические вычисления проникли во все сферы начиная от науки, заканчивая финансовыми услугами. Всем им приходится обрабатывать большое количество информации, с которой справится, разве что, большой вычислительный кластер. Однако он обходится гораздо дороже как в обслуживании так и в содержании, нежели чем профессиональный графический вычислитель (например Nvidia Tesla). Мощнейшие суперкомпьютеры используют GPU как основной вычислительный блок (например, лидирующий в 2013 Titan), что указывает на то, что графические вычисления будут продолжать развиваться и достигать все большей производительности.
Библиографический список
- Боресков А.В., Харламов А.А., Марковский Н.Д. Микушин Д.Н., Мортиков Е.В., Мальцев А.А., Сахарных Н.А., Фролов В.А. «Параллельные вычисления на GPU. Архитектура и программная модель CUDA». – М.: Издательство Московского Университета, 2012. – 336 с. – (Серия «Суперкомпьютерное образование»).
- Описание «What is GPU computing» на сайте Nvidia [Электронный ресурс]. http://www.nvidia.com/object/what-is-gpu-computing.html
- «Истории успеха» на сайте Nvidia [Электронный ресурс]. http://www.nvidia.ru/page/case_studies.html