

При эксплуатации компьютера по самым разным причинам возможны порча или потеря информации на магнитных дисках. Это может произойти из-за физической порчи магнитного диска, неправильной корректировки или случайного уничтожения файлов, разрушения информации компьютерным вирусом и т.д. Для того чтобы уменьшить потери в таких ситуациях, следует иметь архивные копии используемых файлов и систематически обновлять копии изменяемых файлов [1-3].
В последних десятилетиях мы наблюдали беспрецедентный взрыв количества оцифрованной информации в связи с бурным развитием Всемирной Паутины (WWW). Поэтому, одной из основных проблем современной информатики является эффективное сжатие данных для передачи их по сравнительно медленным каналам связи. Также в связи с усложнением современных программных средств, их дистрибутивы занимают все большие объемы памяти.
Алгоритм, лежащий в основе архиватора. Ядром архиватора является метод BWT лексикографической сортировки матрицы циклических перестановок входной строки, который позволяет эффективно раскрывать энтропийные взаимозависимости входных данных. Для устойчивости сортировщика на высокоизбыточных данных ведущими специалистами в области сжатия предложен алгоритм сортировки удвоением, который на данный момент используется в большинстве современных архиваторов. После глубоких теоретических и практических исследований данного алгоритма, было установлено, что он достаточно неэффективен на типичных данных. Поэтому нами был разработан уникальный в своем роде метод позволяющий эффективно сортировать типовые файлы и не теряющий своей эффективности на вырожденных данных. Он основан на сортировке Бентли-Седжвика с использованием авторской технологии Pixar. Отличительной его особенностью является интенсивное использование сверхбыстрой кэш-памяти CPU, что обуславливает высокую скорость сортировки, несмотря на нелинейную зависимость последней от размера блока. Важным преимуществом выбранного метода является высокий потенциал в поддержке современных аппаратных инноваций, таких как 64-битность архитектуры процессоров и Hyper-Threading .
В решении проблемы эффективного сжатия BWT-выхода ключевым моментом является LUP (List Update Problem). Эта проблема заключается в выборе способа эффективного обновления списка символов для лучшего предсказания однородности контекстов в исходном файле. Нами было разработано собственное решение, gmtf, которое сочетает в себе простоту алгоритма и сложное моделирование. Для улучшения энтропийных характеристик выхода gmtf был предложен специализированный метод кодирования длин повторов, который позволяет более эффективно использовать контекстную избыточность в преобразованном файле.
Последним этапом BWT-преобразования является использование энтропийного order-0 кодера, который в отличие от традиционных кодировщиков избыточности позволяет наиболее близко подойти к идеальному кодеру Шеннона. По результатам наших последних исследований именно он позволяет наилучшим образом интерпретировать выявленные BWT логические взаимозависимости данных.
Последним рубежом в борьбе за лучшее сжатие между архиваторами является построение алгоритмов, использующих особенности типовых данных, например, текстов или исполнимых файлов, алгоритмов предобработки или препроцессинга. На данном этапе реализованы словарные алгоритмы преобразования текстов, алгоритмы модификации труднопредсказуемых символов и моделирование логики компилятора. Эти методы позволяют достичь 5-15% улучшения сжатия на типовых файлах, что позволяет на равных конкурировать с современными программами сжатия данных.
Нами были разработаны и реализованы авторские решения проблем высокоэффективного сжатия контекстно-избыточных данных, а также проведены теоретические исследования, доказывающие их эффективность. Как результат, на данный момент создана бета-версия полноценного компрессора, результаты которой в сравнении с другими программами сжатия данных подтверждают теоретические оценки. Тем не менее, остаются потенциальные возможности улучшения производительности.
Описание реализованных алгоритмов.
- HydraY codename “Windforce” – BWT processor:
В отличие от большей части современных BWCA архиваторов мы не используем преимущества концепции сортировки удвоением. В результате её глубокого исследования был обнаружен серьёзный недостаток – она не позволяет использовать следующее важное свойство BWT: для получения последнего столбца не обязательно иметь всю матрицу перестановок. Другими словами, нам не обязательно упорядочивать набор рядом стоящих строк(группу), если все они заканчиваются одним и тем же символом – это не повлияет на выход BWT. Это положение легло в основу нашей технологии PiXar. Она позволяет значительно ускорить обработку высоко избыточных данных, предоставляя возможность использовать алгоритм Бентли-Седжвика для сортировки строк матрицы перестановок. Предварительно список строк сортируется расстановкой по первым 4-м символам.
- Lynx – gmtf+grle processor
В качестве подходящего решения LUP был разработан собственный метод gmtf. Он заключается в том, что найденный символ перемещается не в начало списка, а к ближайшей границе. Массив границ был подобран экспериментально и является константой алгоритма, хотя возможность его динамической адаптации к входному потоку имеет большие перспективы для улучшения сжатия. Тестирование показало явное превосходство данного метода над известными решениям List Update Problem: MTF,MTF0 и др. Длинные последовательности нулей выхода gmtf эффективно кодируются grle. Этот метод, отдалённо напоминающий RLE – кодирование длин повторов, позволяет наиболее эффективно кодировать так называемые “хорошие” фрагменты gmtf-выхода.
- Order0 – arithmetic coder
В результате вышеописанных преобразований получаются два потока разной статистики: gmtf и grle ранги. Заключительной стадией сжатия является их обработка энтропийным кодером. В качестве такового был выбран адаптивный арифметический кодер Дмитрия Субботина и Владимира Семенюка.
- Ptax – distance coder
Этот метод не вошел в текущую реализацию, но был активно используемым нами ранее. Он был реализован в высокоэффективном двухпроходном варианте. Асимптотическая сложность порядка O(N). Для непосредственного кодирования расстояний использовалась техника представления числа в виде суммы некоторых элементов последовательности Фибоначчи. Метод был отстранён на второй план в связи с малой эффективностью с точки зрения степени сжатия.
- Warden/Sylph – Intel 32 Architecture Preprocessor (7-15% compression gain).
Общая идея данного метода состоит в переходе от относительных адресов к абсолютным, например, при кодировании команд E8h и E7h (“CALL” и “JUMP” соответственно). Таким образом, слабо предсказуемые относительные смещения в коде программы преобразуются в абсолютные адреса в данном сегменте кода, что позволяет предсказывать старшие байты смещения. По теоретическим оценкам и практическим выводам аналогичное кодирование для команды “JUMP” проводить не стоит. Важное практическое применение имеет разработка технологии вычленения команд из сегмента кода для более точного определения команд, подлежащих кодированию. Эта технология в данный момент находится в альфа-тестировании.
Lich/Vampire/Wraith – Length-Index Preserving Transformation (5-10% compression gain)
Связка данных программ реализует LIPT-препроцессор для улучшения сжатия текстовых файлов. Основная идея заключается в построении словаря некоторого языка на основании анализа множества файлов на определенном языке, причем внутри словаря фразы разбиты на группы по длине, а внутри каждой такой группы отсортированы по частоте использования в языке (эту часть метода осуществляет Wraith). Далее слова обрабатываемого файла заменяются на строки следующего вида: <escape><word length><word index><flags>, где длина слова и его индекс в словаре кодируются с помощью записи в позиционной системе счисления, цифрами которой являются фиксированные символы, а флаги обозначают начинается ли слово с большой буквы или состоит из произвольно капитализированных символов (в последнем случае нужно записывать маску капитализации), определяющую какие из символов слова капитализированы).
Таким образом, в файле создаются искусственные, но стабильные контексты, что обуславливает высокий прирост сжатия. Важно отметить, что словарь является фиксированным и в архиве не передается, т.е. словарь задается заранее.
Алгоритм программы. Показан на рис.1.
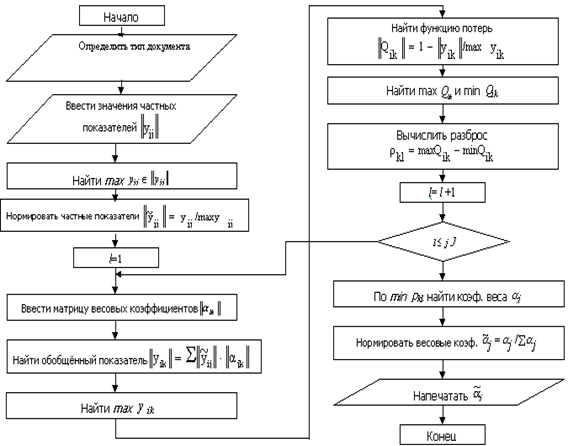
Рис. 1. Алгоритм программы
Интерфейс программы. Интерфейс программы довольно прост и эргономичен. В оболочке программы отсутствуют пестрые краски что положительно сказывается на глазах и не вызывает усталость (Рис. 2).

Рис 2. Интерфейс программы
В статье были разработаны и реализованы решения проблем высокоэффективного сжатия контекстно-избыточных данных, а также проведены теоретические исследования, доказывающие их эффективность. Как результат, на данный момент создана программа полноценного компрессора, результаты которой в сравнении с другими программами сжатия данных подтверждают теоретические оценки. Тем не менее, остаются потенциальные возможности улучшения производительности. В перспективе все исполняемые файлы будут заменены динамическими библиотеками, которые будут обмениваться данными с интерфейсом через стандартные функции операционной системы. Также в виде динамических библиотек будет реализована поддержка других форматов архивов (но только на чтение).
Библиографический список
- Заргарян Е.В., Заргарян Ю.А., Коринец А.Д., Малышенко И.М. Анализ методов компрессионного сжатия информации // Современные научные исследования и инновации. 2015. № 10 [Электронный ресурс]. URL:http://web.snauka.ru/issues/
2015/10/58253 - Заргарян Е.В., Заргарян Ю.А., Мищенко А.С., Лимарева Н.В. Проектирование автоматизированного рабочего места врача-терапевта санатория // Современная техника и технологии. 2014. № 11 [Электронный ресурс]. URL: http://technology.snauka.ru/2014/11/4881
- Заргарян Е.В., Заргарян Ю.А., Коринец А.Д., Малышенко И.М. Проектирование автоматизированного рабочего места сотрудника регистратуры санатория // Современная техника и технологии. 2014. № 12 [Электронный ресурс]. URL: http://technology.snauka.ru/2014/12/5013