Сегодня к распределенным вычислительным системам относят: вычислительные кластеры, SMP – симметричные мультипроцессоры, DSM – системы с распределенной разделяемой памятью, MPP – массово-параллельные системы и мультикомпьютеры. Данная классификация основывается на функциональных возможностях с точки зрения конечного пользователя. Также в литературе [6-11] встречаются подходы к построению структурно-функциональной систематизации распределенных вычислительных систем. Классификация Флинна различает следующие параллельные архитектуры: SIMD, MIMD, MISD и MSIMD. [1,12,13].
Следует отметить, что классификация Флинна и более поздние – Хокни, Фенга, Хендлера не различают системы распределенных вычислений по принципу взаимодействия процессов. В то время как, именно взаимодействие процессов – есть общее свойство, которое может обеспечить возможность повышения производительности масштабируемых систем. Рассмотрим классификацию распределенных вычислительных систем с позиции взаимодействия процессов в них.
Мультикомпьютеры – множество вычислительных модулей, объединенных в единую сеть, каждый вычислительный модуль управляется своей операционной системой. Вычислительные модули, находящиеся в узлах мультикомпьютера, не имеют общих структур, имеют высокую степень готовности к исполнению и состоят, как правило, из отдельных компьютеров или различных комбинаций кластеров, MPP-, DSM-, SMP-систем. Мультикомпьютер в распределенной операционной системе отражается, как единый виртуальный однопроцессорный вычислительный ресурс.
Взаимодействие процессов в мультикомпьютерах реализовано посредством явных операций связи между вычислительными модулями. Примером могут служить библиотеки MPI. В мультикомпьютерах не реализована единая очередь выполнения процессов, а распределение процессов по вычислительным узлам реализует согласованный сетевой протокол[7].
Кластер — наиболее популярная на сегодняшний день технология распределенных вычислений. Кластер описывается в виде набора отдельных вычислительных компьютеров, которые рассматриваются кластерной ОС, как системное программное обеспечение, либо программное приложение, а со стороны пользователя, как единая монолитная вычислительная система. Кластеры имеют крайне высокую степень готовности к исполнению, именно благодаря этой особенности они получили широкое распространение. Высокая степень готовности обеспечивается из-за отсутствия совместного использования оперативной памяти и благодаря тому, что в каждом вычислительном узле работает своя собственная автономная копия ОС и лишь обменивается результатами вычислений по сети. Диагностирующее программное обеспечение постоянно контролирует состояние вычислительных узлов, а при выходе из строя одного из них, оставшиеся ресурсы передаются под управление ближайшего вычислительного узла. В процессе объединения компьютеров в кластер для коммуникаций между вычислительными узлами используются прямые межузловые связи, которые осуществляются посредством коммутации пакетов. Системы коммуникаций бывают, как самые простые (например, на основе протокола Ethernet), так и сложными высокоскоростными подсетями SCI, MemoryChannel и др.
Разделяют две типичных архитектурных организации вычислительных кластеров: с разделяемыми дисками (рис. 1, а) и без разделения ресурсов (рис. 1, б). Как видно из рисунка в первой архитектурной организации кластера каждый узел имеет доступ к общим дискам с данными, во втором случае каждый вычислительный узел имеет свою оперативную память и дисковое хранилище, тем не менее во второй архитектуре также поддерживается целостный образ ресурса.
Кластер – это высокопроизводительная и хорошо масштабируемая система. К недостаткам кластера можно отнести отсутствие единого адресного пространства, что приводит к большим накладным расходам для обмена сообщениями между узлами[8].
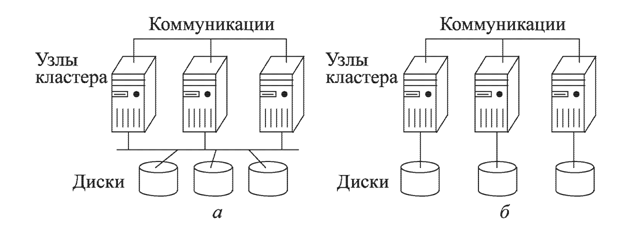
Рис. 1. Кластеры с разделяемыми дисками и без разделения ресурсов.
К примеру, в случае использования стандартного протокола TCP/IP для реализации системы коммуникаций между вычислительными узлами, временные затраты значительно превышают затраты на передачу данных в мультикомпьютерах и SMP-системах. В связи с этим имеет место разработка специализированных протоколов для систем коммуникаций внутри кластера.
Кластера наиболее часто используются для решения хорошо структурируемых, научных приложений[9].
SMP-системы строятся на базе десятков процессоров, оперирующих общей глобальной оперативной памятью и объединенных общей коммуникационной системой (рис. 2).
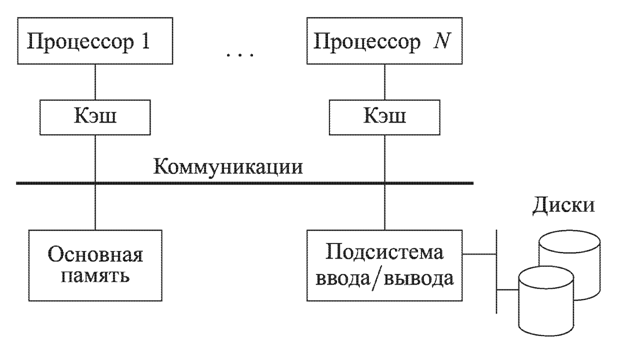
Рис. 2. Структура SMP-системы
Различают несколько вариантов SMP-архитектур с одной системной шиной и множеством системных шин. Для связи процессоров используются специализированные коммутаторы[9].
Доступ ко всей основной памяти имеет каждый процессор. В SMP-системах реализована особая система прерываний работы одних процессоров при повышенном приоритете у других. Коммуникационная подсистема имеет значительную пропускную способность для быстрого доступа к памяти. В ряде случаев процессоры системы имеют несколько уровней собственной кэш-памяти.
Именно благодаря процессорной кэш памяти не происходит коллизий и перегрузок обращений к общей памяти, время доступа к общей памяти примерно одинаково для любого процессора системы.
Такие системы имеют еще одно название – UMA (Uniform Memory Access). ОС в таких системах работает с единым адресным пространством общей глобальной памяти.
Реальным недостатком таких систем является проблема когерентности данных, т.е. согласованности изменений значений в кешах и общей памяти. Решение проблемы когерентности данных достигается двумя способами: записью с обновлением копий данных и записью с аннулированием копий данных. Для реализации обоих методов используются специальные контролирующие подсистемы, которые фиксируют обращения к общей памяти из кэша и запускают один из вышеописанных процессов.
Такой обмен сообщениями в разы быстрее чем обмен данными в кластерах и мультикомпьютерах, поэтому SMP-системы получили широкое распространение для обработки значительного числа коротких транзакций, что очень свойственно фондовым и банковским приложениям[10].
DSM-системы являются расширением SMP-систем. В отличие от SMP-систем имеют, помимо кеша, экземпляр локальной памяти в каждом процессорном комплекте. Также как и в SMP-системах поддерживается общее адресное пространство. Поэтому DSM-системы получили другое название NUMA (Non-Uniform Memory Access) – неоднородный доступ к памяти[11].
Фактически DSM-системы предлагают альтернативный метод решения проблемы когерентности данных, отказавшись от аппаратного контроля за обращениями к памяти и переложив этот процесс на программный слой виде специализированных программ контроллеров. Механизм работы таких контроллеров описан в [11].
Следует отметить, что и у данного способа есть эволюционное расширение – обеспечение когерентности данных в кэш-памяти всех процессорных комплектов. Данный подход реализован в архитектуре ccNUMA (cache coherent NUMA), в котором механизм работы кэша любого вычислительного узла связан с доступом к локальной памяти удаленного узла. Состояния кэшей отслеживаются с помощью специализированных протоколов. Общая структура ccNUMA-системы показана на рис. 3.
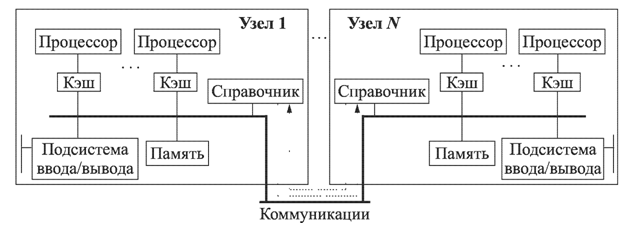
Рис. 3. Структура ccNuma-системы
Массово-параллельные системы (MPP-системы) отличаются большим количеством вычислительных узлов. Эти узлы могут состоять как из одного, так и нескольких процессоров, постоянной памяти и устройств ввода/вывода.
В МРР-системах реализуются архитектуры без разделения ресурсов. Каждый вычислительный узел работает под управлением своей ОС и имеет уникальное адресное пространство памяти. Вычислительные узлы объединяются в систему посредством специализированной коммуникационной средой. В МРР-системах не возникает проблемы когерентности данных. Во многом МРР-системы сходны с мультикомпьютерами.
В отношении МРР-систем следует признать, что классификация МРР-архитектур и используемую при этом терминологию нельзя считать устоявшимися на сегодняшний день.
Таким образом в статье представлена классификация распределенных вычислительных систем с позиции взаимодействия процессов в них.
Библиографический список
- Лукашенко В. В., Романчук В.А. Разработка математической модели реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров //Вестник Рязанского государственного университета имени С. А. Есенина. Научный журнал. –2014. -№ 1/42 С. 176-181.
- Романчук В.А., Ручкин В.Н., Фулин В.А. Разработка модели сложной нейропроцессорной системы // Цифровая обработка сигналов. – Рязань : Информационные технологии, 2012. – №4. – С.70–74.
- Ian Foster,The anatomy of the GRID [Text] //Ian Foster Carl Kesselman, Steven Tuecke, International Journal of High Performance Computing Applications.- 2001-№ 15(3). – p. 200-222.
- Ручкин В.Н., Фулин В. А. Архитектура компьютерных сетей // Диалог-МИФИ. Москва, 2008 С. 238.
- Ручкин В. Н. Проектирование и выбор специализированных средств обработки информации // Московский государственный открытый университет. Москва, 1997. С. 128.
- Корнеев В. В. Параллельные вычислительные системы. — М.: Нолидж, 1999. — 320 с.
- Бурцев В. С. Параллелизм вычислительных процессов и развитие архи- архитектуры суперЭВМ. — М.: ИВВС РАН, 1997. — 152 с.
- Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. — СПб.: БХВ-Петербург, 2002. — 608 с.
- Лацис А. Как построить и использовать суперкомпьютер. — М.: Бестсел- Бестселлер, 2003. — 240 с.
- Таненбаум Э. Архитектура компьютера. — СПб.: Питер, 2002. — 704 с.
- High performance cluster computing / Ed. R. Buyya. V. 1. Architectures and systems. V. 2. Programmingandapplications. — NewJersey: PrenticeHall PTR, 1999
- Лукашенко В. В. Математическая модель реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров // Наука, техника, инновации, сборник статей Международной научно-технической конференции. 2014, с. 232-236.
- Лукашенко В.В. Формализация модели нейропроцессорной системы, как grid-системы // Информатика и прикладная математика, межвузовский сборник научных трудов, Рязань, 2013, №19, с. 048-052.