РАСПРЕДЕЛЕННЫЙ АНАЛИЗ КАТЕГОРИАЛЬНЫХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ДЛЯ НЕПРЕРЫВНОГО ПРОИЗВОДСТВА
1Санкт-Петербургский политехнический университет Петра Великого, студент
2Санкт-Петербургский политехнический университет Петра Великого, кандидат технических наук, доцент
Аннотация
Статья посвящена подходу к выявлению паттернов в последовательностях категориальных данных для непрерывного производства. Исследование современных тенденций развития производственной сферы подтверждает необходимость разработки подходов, применимых для анализа больших объемов данных. Описываемый подход включает в себя методы распределенной обработки, позволяющие проводить анализ данных в потоке для обеспечения адекватного времени отклика.
Ключевые слова: вычисления на кластерах, выявление паттернов, категориальные последовательности, потоковые данные, распределенный анализ
Библиографическая ссылка на статью:
Шереметова Е.И., Потехин В.В. Распределенный анализ категориальных последовательностей для непрерывного производства // Современная техника и технологии. 2017. № 5 [Электронный ресурс]. URL: https://technology.snauka.ru/2017/05/13383 (дата обращения: 30.07.2026).
В области анализа данных последовательностью называют упорядоченный набор элементов, каждый из которых может быть числовым, категориальным (состоящим из нескольких качественных значений), или смешанным [1, с. 1]. Расположение таких элементов в последовательности строго определено в зависимости от логического порядка их следования (категориальные последовательности) или от времени их появления (временные ряды). На сегодняшний день анализ последовательностей данных широко применяется во многих областях – медицине, биологии, производстве, однако существующие на данным момент подходы используют алгоритмы, работа которых существенно зависит от размерности входных данных. В данной статье представляется подход к анализу категориальных последовательностей с использованием технологии распределенной обработки, позволяющей эффективно работать с данными, размеры которых превышают доступную оперативную память.
ВЫБОР АЛГОРИТМА ДЛЯ АНАЛИЗА ПОТОКОВЫХ ДАННЫХ
При работе с потоковыми данными зачастую возникают трудности, которые можно разделить на следующие категории:
-
Проблема передачи данных на вход программы из-за высоких скоростей генерации новых данных;
-
Проблема выполнения операций вычисления сложных функций с использованием большого количества входных данных, которые быстро обновляются, что влечет за собой серьезные нагрузки на вычислительную инфраструктуру;
-
Проблема хранения данных (временно или в целях последующего использования их в долгосрочной перспективе).
Исследование литературы по вопросам выявления паттернов в категориальных последовательностях показало, что наиболее популярными методами являются подходы, разработанные группой исследователей IBM Research [2, 3], которые представили алгоритмы AprioriSome, AprioriAll, DynamicSome и SPADE. Однако применение указанных подходов не позволяет решить проблемы, специфичные для потоковых данных. В первую очередь это связано с использованием в данных алгоритмах чрезмерно сложных структур данных, а также с большим количеством запросов к базе данных. Таким образом, данные алгоритмы трудны для распараллеливания, что делает трудоемким создание распределенной системы на их основе.
Намного более пригодными для распараллеливания являются алгоритмы поиска подпоследовательностей FreeSpan, PrefixSpan и GSP. Сравнение масштабируемости этих алгоритмах на редуцированном наборе данных, включающем в себя 40000 последовательностей, представлены на рисунках 1, 2.
На рисунке 1 изображены графики зависимоссти времени выполнения алгоритма от значения параметра минимальной поддержки, характеризующего процент различия между последовательностью данных и входящей в нее подпоследовательностью. Из графиков видно, что наилучшей масштабируемостью обладает алгоритм PrefixSpan [4, с. 3].
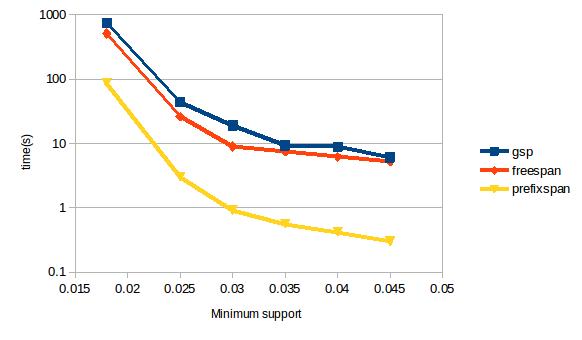
Рисунок 1. Проверка масштабируемости времени выполнения алгоритмов GSP, FreeSpan, PrefixSpan
На рисунке 2 представлено сравнение использования памяти алгоритмами GSP и PrefixSpan при различных значениях параметра минимальной поддержки. Из графиков видно, что PrefixSpan более стабилен в использовании памяти.
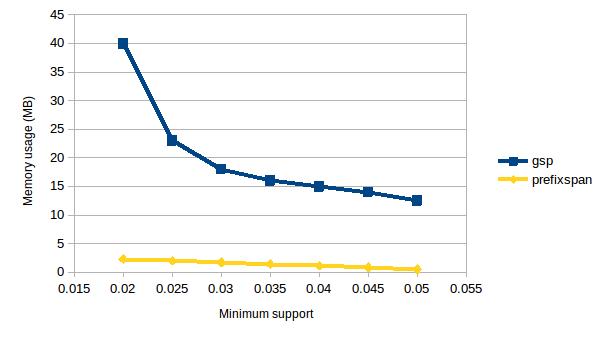 Рисунок 2. Проверка масштабируемости использования памяти алгоритмами GSP и PrefixSpan
Рисунок 2. Проверка масштабируемости использования памяти алгоритмами GSP и PrefixSpan
РАСПАРАЛЛЕЛИВАНИЕ ВЫЧИСЛЕНИЙ
Исследование масшлабируемости алгоритмов показало, что алгоритм PrefixSpan применим для решения задачи анализа категориальных последовательностей, поскольку имеет хорошие показатели масштабируемости. Однако для адаптации к специфике решаемой задачи (необходимость обработки больших объемов данных), требуется использование дополнительных мер по ускорению алгоритма, а также сокращению объема занимаемой памяти. Обе эти проблемы могут быть успешно решены с помощью технологии MapReduce, которая с одной стороны позволят занимать наименьший объем в памяти, с другой стороны дает возможность сохранять наибольший объем информации для анализа, а также сокращать время выполнения алгоритма. В обобщенном виде технологию MapReduce можно представить в виде схемы, изображенной на рисунке 3.
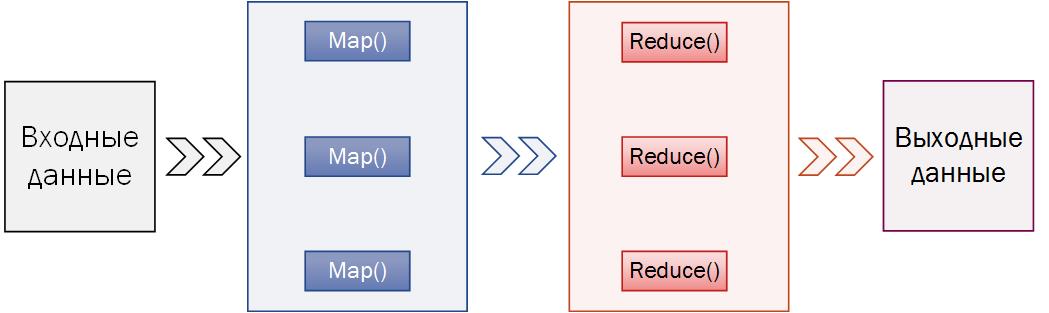
Рисунок 3. Технология MapReduce
Использование данной технологии применительно к решаемой задаче заключается в адаптации выбранного алгоритма (PrefixSpan) к данной технологии – представлении функций, используемых в алгоритме, в виде комбинации функций Map и Reduce. Назначение данных функций подробно описано в [5].
ОБОБЩЕННЫЙ ВИД СИСТЕМЫ
В связи с увеличением числа данных, подлежащих обработке и анализу, в системы распределенного анализа требуется вводить в инфраструктуры, обеспечивающие гибкую работу с кластерами, на которых выполняются вычисления. Amazon EMR предоставляет управляемую инфраструктуру, которая способна эффективно обрабатывать большие объемы данных на динамически масштабируемых кластерах Amazon EC2.
На рисунке 4 представлена обобщенная архитектура системы анализа потоковых данных на кластерах с использованием облачной инфраструктуры Amazon ERM.
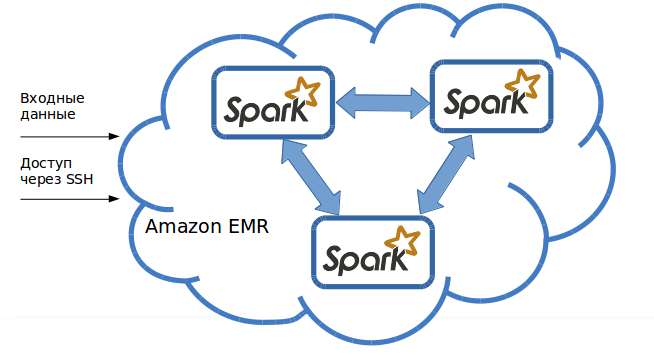
Рисунок 4. Архитектура системы
Выявление паттернов в последовательностях категориальных данных предлагается выполнить на основе алгоритма PrefixSpan, адаптированного для распределенной работы с использованием технологии MapReduce. Модель MapReduce может быть реализована на платформе анализа данных Apache Spark, которая представляет собой новую кластерную распределенную вычислительную среду, предназначенную для итерационных вычислений с низкой задержкой [6, с. 3].
Данный фреймворк позволяет эффективно распределять нагрузку по кластерам при выполнении операций алгоритма PrefixSpan. Spark доступен для запуска в Amazon EMR, благодаря чему разворачивание распределенной кластерной архитектуры становится доступнее. Кроме того, программый интерфейс Apache Spark доступен на языках программирования высокого уровня Java, Python и Scala, что обеспечивает простоту поддержки и интеграции с другими компонентами, а также последующего расширения системы.
Библиографический список
- Kerdprasop K., Kerdprasop N. Sequence Analysis Technique to Detect Performance Patterns in Complex Manufacturing Process. – 2013.
- Agrawal R., Srikant R. Mining sequential patterns //Data Engineering, 1995. Proceedings of the Eleventh International Conference on. – IEEE, 1995. – С. 3-14.
- Zaki M. J. SPADE: An efficient algorithm for mining frequent sequences //Machine learning. – 2001. – Т. 42. – №. 1. – С. 31-60.
- Aloysius G., Binu D. An approach to products placement in supermarkets using PrefixSpan algorithm //Journal of King Saud University-Computer and Information Sciences. – 2013. – Т. 25. – №. 1. – С. 77-87.
- Ekanayake J., Pallickara S., Fox G. Mapreduce for data intensive scientific analyses //eScience, 2008. eScience'08. IEEE Fourth International Conference on. – IEEE, 2008. – С. 277-284.
- Meng X. et al. Mllib: Machine learning in apache spark //Journal of Machine Learning Research. – 2016. – Т. 17. – №. 34. – С. 1-7.
Все статьи автора «Евгения Ивановна Шереметова»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.