

Очевидно, что модели обмена данными в распределенных вычислительных системах важны настолько, что модели параллельных вычислений ассоциируются с конкретными способами взаимодействия процессов. Выделяют несколько основных способов взаимодействия вычислительных процессов в параллельных системах: модель обмен сообщениями, модель разделения общей памяти и модель прямого доступа к удаленной памяти.
Модель обмена сообщениями
Как описано в [12], модель обмена сообщениями часто используется при проектировании различных архитектур масштабируемых вычислительных систем — как без единого адресного пространства (мультикомпьютеры и кластеры), так и с общим адресным пространством (SMP, DSM). Механизм передачи сообщений традиционно используется в моделях распределенной обработки. К примеру, удаленный вызов процедур (RPC — remote procedure call) есть один из способов передачи сообщений. Среды DCOM (Distributed Component Object Model) и СORBA (Common Object Request Broker) работают по принципу вызова метода RPC, представляя собой его объектный вариант. Механизм RPC реализует модель передачи сообщений, в соответствии с ней в распределенных вычислительных системах происходит взаимодействие двух процедур: процедур-клиентов и процедур-серверов.
Реализация механизмов взаимодействий ресурсов и правильная организация среды для взаимодействия вычислительных процессов – есть главные критерии, благодаря комбинации которых и существует огромное количество разновидностей моделей обмена. Под механизмом взаимодействия понимают режимы и характер приема/передачи сообщений.
Существует два режима обмена сообщениями: блокирующий и неблокирующий. При неблокирующем обмене не происходит приостановка взаимодействующих процессов, система ждет завершения процесса приема/передачи. При блокирующем обмене наоборот, происходит приостановка процессов приема/передачи в пользу более приоритетных процессов обмена сообщениями.
Различают три характера обмена сообщениями: синхронный, асинхронный либо асинхронно/синхронный. Синхронный характер выделяется тем, что процесс, при достижении определенного состояния, переходит в режим ожидания, до тех пор пока другой процесс не достигнет соответствующего состояния. Асинхронный характер передачи сообщений осуществляет возврат из процедуры обмена сразу после передачи сообщения без ожидания завершения приема. В случае асинхронно/синхронного характера обмена сообщениями операции передачи сообщений являются асинхронными, а операции приема — синхронными [3-10].
Модель общей памяти
Ситуация, когда один процесс размещает данные в известную ему область памяти, а другой процесс их считывает, называется разделением общей памяти. В реализации такой модели возникает сложность, которая обусловлена необходимостью обеспечения безопасной записи, удаления и чтения данных.
Возникающую трудность принято решать двумя возможными подходами: путем взаимного исключения критических интервалов или путем условной синхронизации процессов. В методе критических интервалов реализована возможность исключительного доступа к общей переменной лишь для одного процесса. Критические интервалы устанавливаются посредством операций синхронизации, таких как: семафоры, блокирование процессов или битов «занято/свободно».
Модель общей памяти наиболее часто используют при проектировании SMP- и DSM-архитектур. Достоинства данной модели состоят в том, что сильно упрощается процесс программирования из-за единого адресного пространства памяти, отсутствия необходимости явного задания операций пересылки сообщений [1-10].
Управление ресурсами в распределенных средах
Очевидно, что помимо механизмов передачи сообщений, модели вычислений реализуют механизмы управления ресурсами в распределенных вычислительных средах. К ресурсам распределенной вычислительной системы относят: вычислительные машины (узлы), файловые системы, системы коммуникаций, ПО, хранилища данных.
Основное назначение систем управления ресурсами — это процесс распределения программных приложений на процессорные узлы или отдельные вычислительные машины.
Обычно выделяют два компонента, которые реализуют данный механизм на уровне программного обеспечения – менеджер ресурсов и планировщик [3-10].
Основная задача менеджера ресурсов – распределение вычислительных ресурсов, аутентификация, создание и миграция процессов. В свою очередь задача планировщика – определение очередности выполняемых (рис. 1).
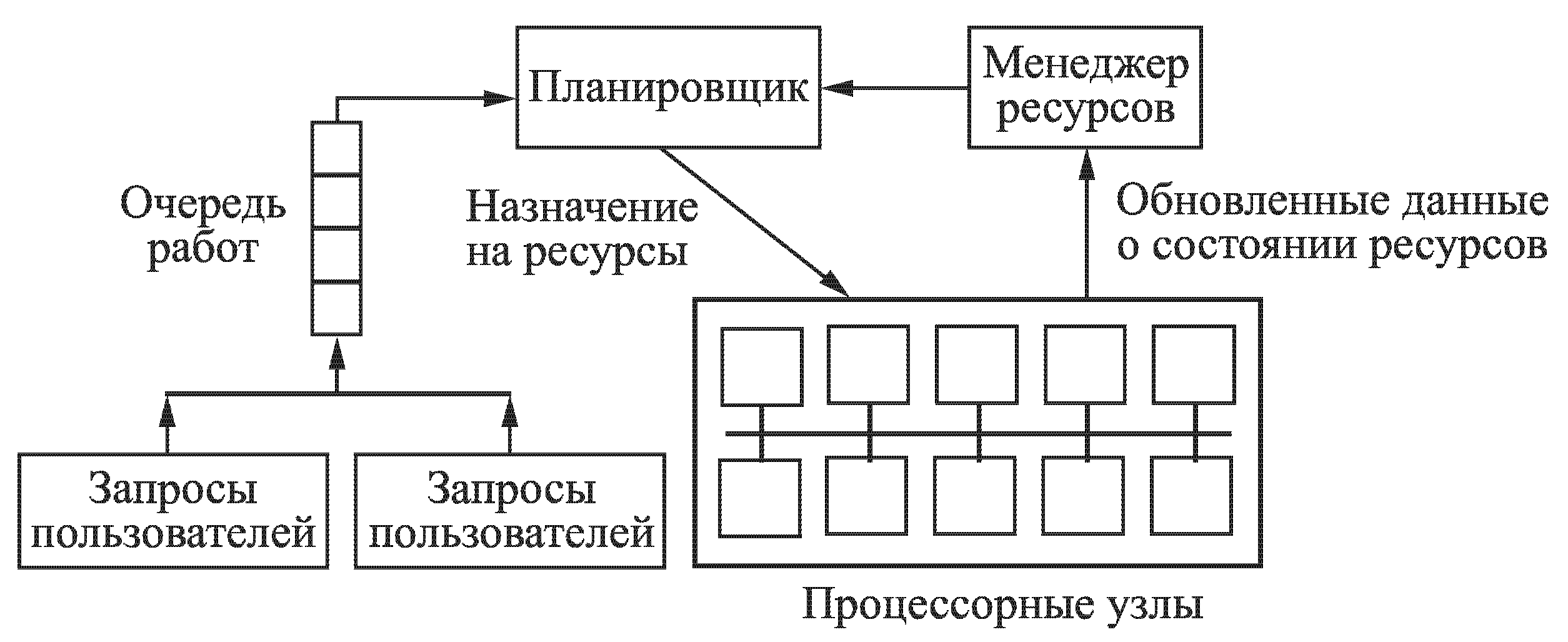
Рис. 1. Типичная структура системы управления ресурсами
Большинство систем управления ресурсами построены по архитектуре «клиент-сервер». Непосредственное использование вычислительных ресурсов осуществляется конечными пользователями через программу-клиент. На непосредственных вычислительных узлах устанавливаются исполнительные программы, которые поддерживают актуальность обновляемых таблиц данных об окружении, в котором и работает система управления ресурсами. В большинстве случаев доступ к вычислительным ресурсам не интерактивный, а посредствам режима пакетной обработки. Запуск в работу системы происходит после отправки пользователем необходимой информации о выходных и выходных данных, необходимой конфигурации аппаратной платформы и т.д.
Выделяют следующие основные функции систем управления ресурсами:
- поддержка очередей и планировка работ;
- балансировка нагрузки;
- миграция работ;
- реализация механизма контрольных точек.
Любая система управления ресурсами в своей основе имеет механизм очередей или диспетчеризации. Существует два наиболее часто используемых принципа построения очередей: «первым пришел — первым обслужен» (FCFS — first come first serve) и «наименее трудоемкая работа выполняется первой» (LWF — least work first).
В большинстве систем управления ресурсами поддерживается совокупность очередей. Работы распределяются в очередях исходя из величин запросов на ресурсы на основе специальных требований к ресурсам. Запросы на ресурсы поступают в виде скриптов команд ввода работы. В итоге диспетчеризация в пакетном режиме позволяет наиболее эффективно использовать вычислительные ресурсы.
Для еще более полного и эффективного использования вычислительных ресурсов используется балансировка нагрузки. Балансировка нагрузки помогает избежать ситуации, когда одна часть узлов перегружена, а другая простаивает. Отсюда вытекает важность механизма планирования работ, который позволяет корректировать поступление работ на выполнения, даже обходя алгоритмы поступления (FCFS, LWF). Балансировка нагрузки осуществляется благодаря функции миграции работ. Функция определяет возможность прерывания, перемещения в другие вычислительные узлы и повторного запуска работы. Функция миграции в системах управления ресурсами также чаще всего строится посредством механизма очередей.
В итоге для конечного пользователя система управления ресурсами должна обеспечить надежное, контролируемое выполнение программ. Случаи любых программно-аппаратных сбоев должны быть исключены механизмом контрольных точек состояния выполнения программ пользователя. Механизм контрольных точек осуществляет, по сути, снимок системы в определенный контрольный момент выполнения программы. Исходя из вышесказанного, механизм контрольных точек, также необходим и при миграции работ.
Таким образом в статье проведен анализ основных вопросов функционирования моделей вычислений и управления ресурсами в распределенных вычислительных средах с перспективой дальнейшего построения математического алгоритмического и программного обеспечения вычислительного кластера на базе нейрокомпьютеров [11].
Библиографический список
- Лукашенко В. В., Романчук В.А. Разработка математической модели реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров //Вестник Рязанского государственного университета имени С. А. Есенина. Научный журнал. –2014. -№ 1/42 С. 176-181.
- Романчук В.А., Ручкин В.Н., Фулин В.А. Разработка модели сложной нейропроцессорной системы // Цифровая обработка сигналов. – Рязань : Информационные технологии, 2012. – №4. – С.70–74.
- Ian Foster,The anatomy of the GRID [Text] //Ian Foster Carl Kesselman, Steven Tuecke, International Journal of High Performance Computing Applications.- 2001-№ 15(3). – p. 200-222.
- Ручкин В.Н., Фулин В. А. Архитектура компьютерных сетей // Диалог-МИФИ. Москва, 2008 С. 238.
- Ручкин В. Н. Проектирование и выбор специализированных средств обработки информации // Московский государственный открытый университет. Москва, 1997. С. 128.
- Корнеев В. В. Параллельные вычислительные системы. — М.: Нолидж, 1999. — 320 с.
- Бурцев В. С. Параллелизм вычислительных процессов и развитие архи- архитектуры суперЭВМ. — М.: ИВВС РАН, 1997. — 152 с.
- Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. — СПб.: БХВ-Петербург, 2002. — 608 с.
- Таненбаум Э. Архитектура компьютера. — СПб.: Питер, 2002. — 704 с.
- High performance cluster computing / Ed. R. Buyya. V. 1. Architectures and systems. V. 2. Programmingandapplications. — NewJersey: PrenticeHall PTR, 1999
- Лукашенко В. В. Математическая модель реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров // Наука, техника, инновации, сборник статей Международной научно-технической конференции. 2014, с. 232-236.
- Лукашенко В.В. Анализ основных вопросов классификаций распределенных вычислительных систем // Современная техника и технологии. 2015. № 4 [Электронный ресурс]. URL: http://technology.snauka.ru/2015/04/6452 (дата обращения: 24.04.2015).